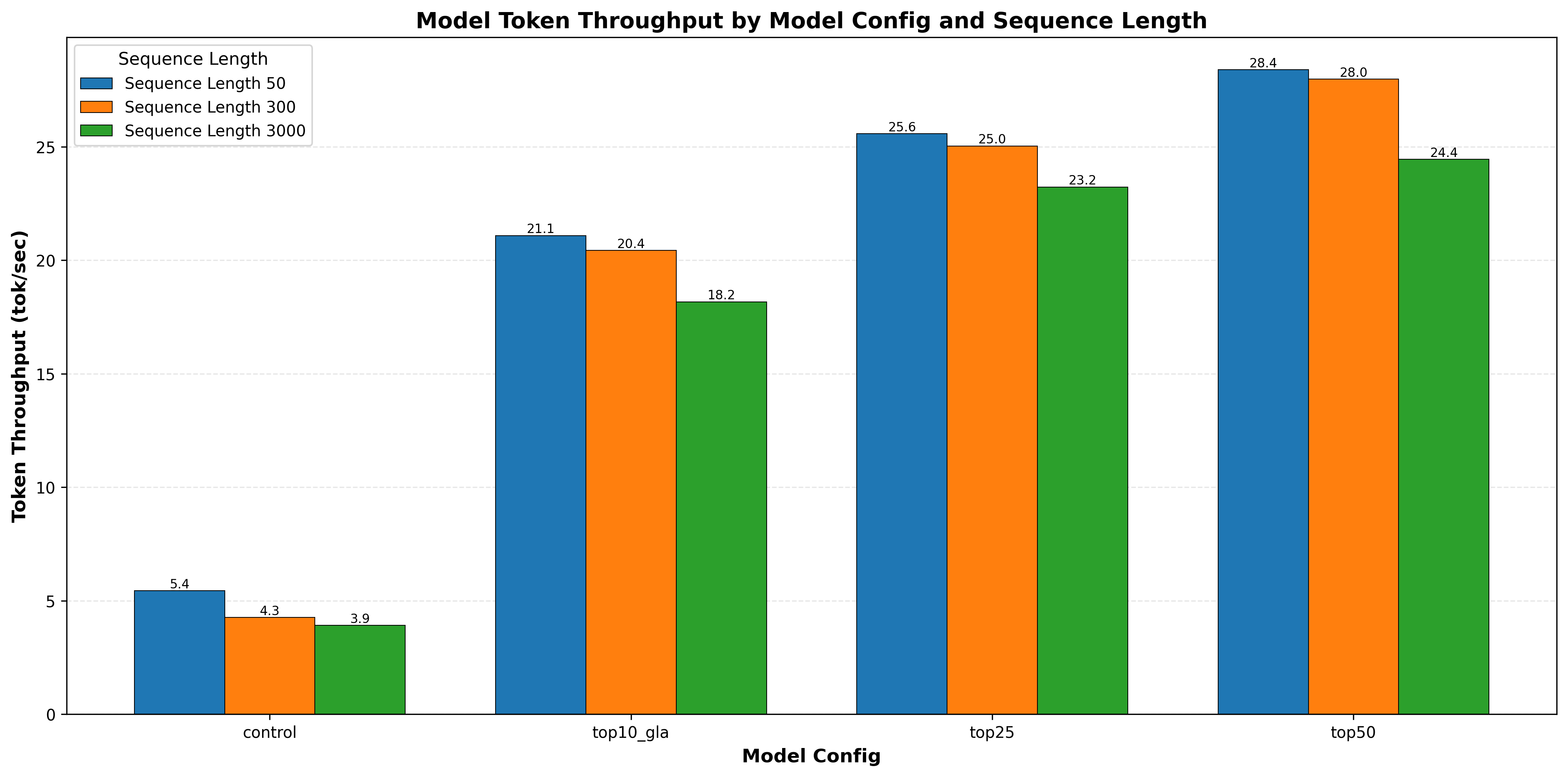
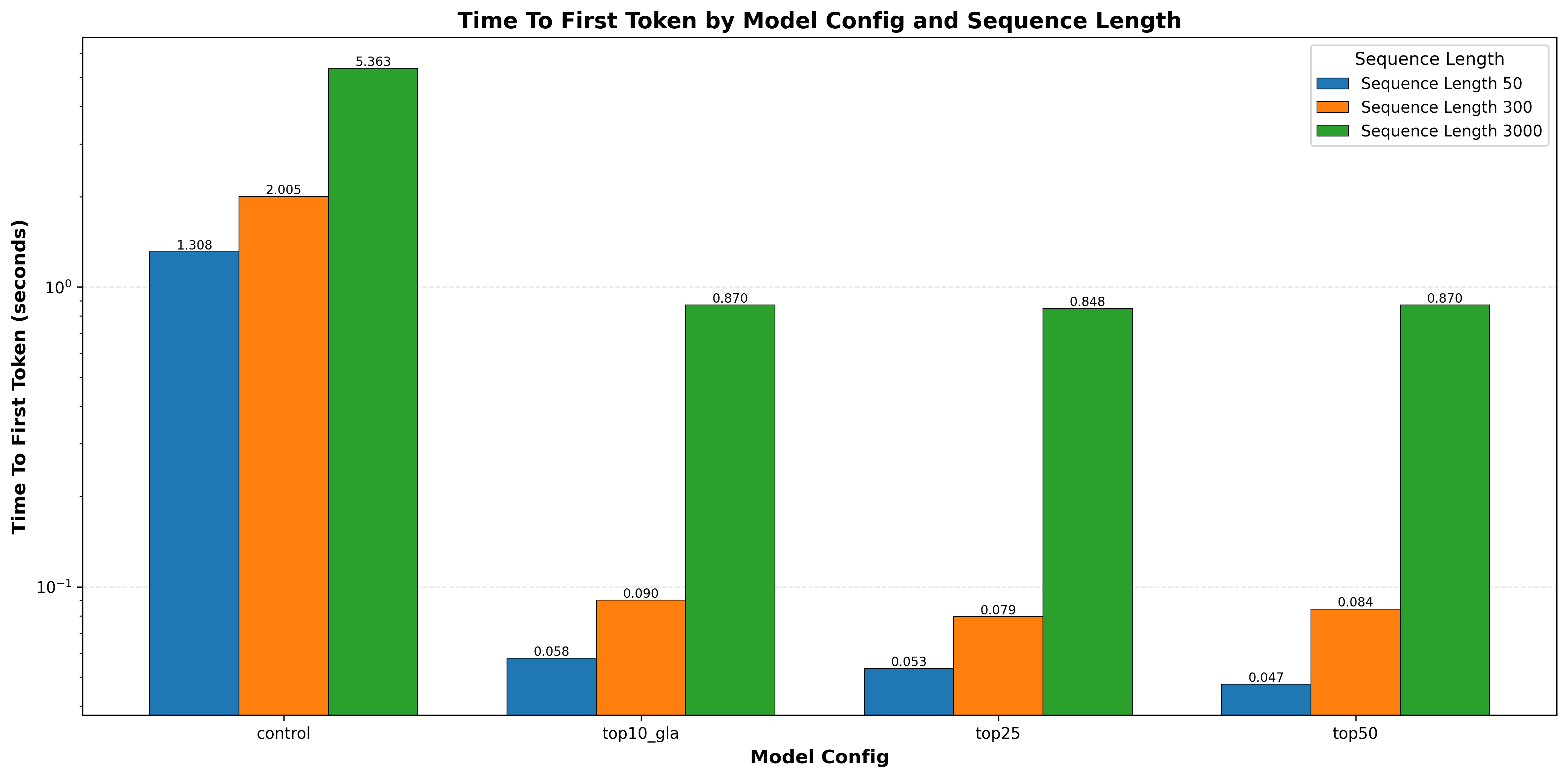
|
Compute-Aware Hybrid Attention Architecture Search: Selective Linear Attention Replacement via Layer-wise Knowledge Distillation |
|||
| Videet Mehta | Sanjith Udupa | Vineet Sharma | |
| Final project for 6.7960, MIT | December 2025 | |||
Stage 0: Layer-wise Linear Attention Training
The first stage trains linear attention replacements for each layer independently. We trained both GLA and RWKV7 variants to measure how well each layer's behavior can be approximated by linear attention, which tells us which layers are good candidates for replacement.
Training Setup
We modified the Qwen3 architecture to create a
Qwen3ForNAS class that outputs the hidden states before
and after any specified layer. For each layer \(l\), we train separate
GLA and RWKV7 blocks to match the teacher's behavior by minimizing MSE
of the output hidden states of the student and teacher models:
\[\mathcal{L}_{\text{MSE}}^{(l)} = \mathbb{E}_{x \sim \mathcal{D}} \left[ \left\| f_{\text{student}}^{(l)}(h^{(l-1)}) - f_{\text{teacher}}^{(l)}(h^{(l-1)}) \right\|_2^2 \right]\]
Training Configuration
We trained each layer on approximately 40 million tokens from the DCLM-baseline-1.0 dataset with batch size 32, sequence length 1024, learning rate 1e-3 with cosine decay to 1e-5, and 10% warmup. To prevent early training divergence, we apply gradient clipping. All training was performed on NVIDIA A6000 GPUs. We trained GLA for layers 1-10 and independently trained RWKV7 for layers 1-28. Training time scaled superlinearly with layer depth.
Normalized Loss
After training the individual layers, we needed a way of comparing the student layers' performance to reproduce their teacher model's hidden states. However, different layers have different activation magnitudes, making the raw MSE values incomparable. We compute a normalized loss that measures the student's error relative to the magnitude of the teacher's update:
\[\mathcal{L}_{\text{norm}}^{(l)} = \frac{\text{MSE}(f_{\text{student}}^{(l)}(h^{(l-1)}), h^{(l)})}{\text{MSE}(h^{(l-1)}, h^{(l)})}\]
A normalized loss of 0.0 means perfect reproduction; 1.0 means the student is no better than passing through the input unchanged.
Layer-wise Training Results

Figure 1: Training curves for GLA student layers showing normalized MSE loss over training.

Figure 2: Training curves for RWKV7 student layers showing normalized MSE loss over training.
RWKV7 Issues
We encountered persistent numerical instability with RWKV7 during Stage 1 training (full model distillation), stemming from mixed precision mismatches between the FLA library's RWKV7 implementation and our teacher model's precision requirements. These floating point arithmetic errors proved difficult to resolve within our compute constraints. As a result, we were unable to successfully complete Stage 1 distillation for any hybrid model configurations that included RWKV7 layers. We therefore proceeded with only GLA layers for the final hybrid model configuration used in Stage 1.
Identifying the Best Layers
After training each layer, we ranked them by their final normalized loss. Based on our experiments, we constrained GLA to layers 1-10. For RWKV7, we trained layers 1-28 and observed similar Stage 0 training results with comparable normalized loss values to GLA, indicating that RWKV7 layers were also capable of approximating the teacher model's behavior during Stage 0. However, we ultimately did not use RWKV7 layers in our Stage 1 hybrid model because Stage 1 distillation consistently failed with RWKV7 layers due to the numerical instability issues described above. The results for both GLA and RWKV7 in Stage 0 revealed a clear pattern: middle layers (roughly layers 8-14) have significantly higher normalized loss than early or late layers, suggesting this pattern holds across different linear attention mechanisms.
This finding aligns with prior work on transformer interpretability. Clark et al. [5] showed that early layers primarily detect local syntactic patterns while middle layers handle more complex semantic relationships. Tenney et al. [6] demonstrated that the "classical NLP pipeline" emerges across layers, with syntax in early layers and semantics in middle layers. Our results suggest that the complex semantic operations in middle layers fundamentally require the expressivity of softmax attention, while the more local computations in early layers can be approximated by linear attention.
| Rank | Layer | Normalized Loss |
|---|---|---|
| 1 | 3 | 0.0003 |
| 2 | 9 | 0.1059 |
| 3 | 10 | 0.1186 |
| 4 | 7 | 0.2129 |
| 5 | 8 | 0.2396 |
| 6 | 1 | 0.3459 |
| 7 | 2 | 0.3585 |
| ... | ... | ... |
| Worst | 6 | 0.4688 |
Table 1: GLA layers ranked by normalized distillation loss. Lower loss indicates better suitability for replacement.
The standout result is layer 3, which achieves a normalized loss of just 0.0003. This layer appears to perform computations that are nearly linear in nature, making it an ideal candidate for replacement.
The normalized loss is crucial for fair comparison. Without it, we would incorrectly conclude that layers with smaller activations are easier to replace.
The pattern of middle layers being hardest to replace aligns with findings from interpretability research showing that middle layers handle more abstract reasoning.